
上一篇我們用 CartPole 了解如何實作 RL。今天來介紹自己的 RL project,更加深實作概念吧。
RL 非常適合應用在訓練遊戲 AI,而我在 Stanford CS229 的 project 正是利用 RL 訓練 AI 玩撞球遊戲。總共用到了三種 model,過程中也感受到 RL 真的不太容易訓練好。
接著我們就來看看這個 project,並認識不同的 RL algorithm 吧。
程式碼、report、poster 都在 GitHub: pyliaorachel/CS229-pool。
目標很簡單,就是讓我們的 model 學會打撞球。

—— Pool game。[1]
具體來說的 formulation 如下:
我們介紹三種 RL algorithm 來訓練我們的 AI。
Q-table 在 Day 25 介紹過了。簡單來說,Q-table 是用 lookup table 來 approximate Q-value function,並用 Q-learning 訓練的一個方法。
Q-learning update rule 再看一次:
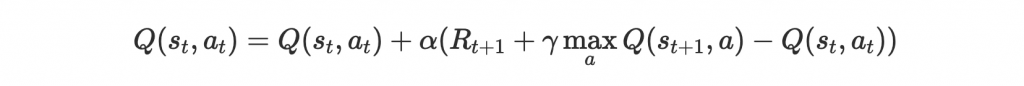
跟前面提到的不同的是,在這個任務裡,我們的 state 和 action 都是連續值,兩個都要 discretize 才能建立一個 lookup table。
實作中,我們將 state 的 x, y 各 discretize 成 50 個區間,擊球角度 discretize 成 18 個區間,力道 discretize 成 5 個區間。這樣會有 50 x 50 個 state 和 18 x 5 個 action,lookup table 大小為 50 x 50 x 18 x 5。
DQN 前幾篇介紹 Atari AI 有介紹過,簡單來說是用 neural network 來 approximate Q-value function。這樣就不用像 Q-table 一樣必需 discretize input 了。
Asynchronous Advantage Actor-Critic (A3C) 有個很讓人摸不著頭緒的名字,但原理並不難。
在 RL 可以訓練兩種 network,一種是 policy network,input state 預測每個 action 的機率。另一種是 value network,input state 預測 state value 或 Q-value。而 A3C 結合了兩種方式,訓練一個 network 預測 action 機率以及 state value。
Actor-Critic 指的就是讓 policy network 當 actor 負責選擇 action,value network 當 critic 負責估計 state 的好壞,而 actor 會根據 critic 給的 value 來更新 model。
Advantage 指的是 actor 在 state s 做出 action a 的優勢。具體來說,大概可以用做出 action a 獲得的 reward R 及 critic 給的 value V(s) 之間的差距 A = R - V(s) 來表示。而 A3C 並不像一般 model 用 discounted reward 而是用 advantage 來訓練。也就是說,比起告訴他你選的 action 有多好,告訴他你選的 action 比預期來得好多少,會讓訓練更有效率,因為這樣 model 更可以知道自己的不足。
最後 asynchronous 指的是我們讓很多 worker 同時跟環境互動汲取經驗學習,比起只有一個 worker 更有效率。具體來說,A3C 會有一個 global network,還有很多 worker 同時跟環境互動,並且把經驗 (state, action, reward) 回報給 global network。大概收集足夠的量,global network 就會根據這些經驗進行學習。如此一來可以有效汲取大量且多樣的經驗,network 也能訓練得更好。
A3C 的 action output 可以是 continuous 或 discrete。Continuous 的話我們會預測一個 normal distribution 的 mean 和 variance,而 discrete 的話就跟 classification 一樣預測每個 discrete action 的機率。我們兩種都有實作做比較。
我們總共有五個 method,Q-table、DQN、A3C with continuous action、A3C with discrete action 四個主要 algorithm,以及 random action 作為 baseline。
我們分別做了兩顆球和四顆球的實驗,其中一顆是白球。
兩顆球實驗中,訓練了 1000 episode 結果如下:

—— 兩顆球實驗中,五個 method 的平均 reward 趨勢。

—— 兩顆球實驗中,五個 method 的平均 reward、訓練時間和空間。
首先可以看到的是 Q-table 成果最好。我們發現 Q-table 學會用六下打進某個洞,所以效果不算太差。但缺點就是訓練時間太長,以及 lookup table 佔用太多空間了,而這只是兩顆球的實驗。因此 Q-table 不太適合 generalize 到更複雜的設定中。
DQN 和 A3C 效果滿普通的,訓練也不太穩定。A3C continuous 一開始還學得比隨便亂打還差,肯定是中途學壞了,後來可能跳脫 local minimum 才逐漸有起色。DQN 和 A3C discrete 都是預測 discrete action,類似於做 classification,我們也發現這種訓練比預測 normal distribution 穩定多了。而且 neural network 的 discritization 也能切得比 Q-table 細,所以會推薦大家要玩 RL 的話先從訓練 discrete action output 開始。
A3C 的訓練時間和佔用空間都非常有效率,其實可以訓練更久試試看,效果應該不錯,只是當時沒有時間再訓練下去了。此外,exploration 的設定可以再提高一些,讓 model 嘗試更多種打法,比較不容易被困在 local minimum。
我們其實還有四顆球的實驗結果,不過兩顆球就夠糟了,四顆球的結果也不太有意義。有興趣可以去看 report。
最後一樣簡單看一下重點部位的 code。我們看一下 A3C with discrete action 的就好。
首先是 global network:
class Net(nn.Module):
def __init__(self, s_dim, a_dim, h_dim):
super().__init__()
self.s_dim = s_dim
self.a_dim = a_dim
# Actor
self.a1 = nn.Linear(s_dim, h_dim)
self.a21 = nn.Linear(h_dim, a_dim[0])
self.a22 = nn.Linear(h_dim, a_dim[1])
# Critic
self.c1 = nn.Linear(s_dim, h_dim)
self.v = nn.Linear(h_dim, 1)
def forward(self, x):
a1 = F.relu(self.a1(x))
logits1 = self.a21(a1)
logits2 = self.a22(a1)
c1 = F.relu(self.c1(x))
values = self.v(c1)
return logits1, logits2, values
Actor 和 critic 都是簡單的 feed-forward network。Actor 預測兩種 action,擊球角度和力道。
再來是每個 worker 和環境互動:
class Worker(mp.Process):
def __init__(self, gnet, opt, global_ep, global_ep_r, env_params, hidden_dim, episodes, episode_length, model_path=None):
super().__init__()
self.env_params = env_params # game environment setting
self.hidden_dim = hidden_dim
self.gnet = gnet # global net
self.opt = opt # optimizer
self.episodes = episodes # total episodes
self.episode_length = episode_length # number of timesteps in an episode
self.g_ep = global_ep # total episodes so far across all workers
self.g_ep_r = global_ep_r # total average rewards so far across all workers
self.gamma = 0.8 # reward discount factor
def run(self):
# set up game environment
env = PoolEnv(**self.env_params)
# worker network
self.lnet = Net(env.state_space.n, env.action_space.n, self.hidden_dim)
# start gathering experience
total_steps = 1
while self.g_ep.value < self.episodes:
next_state = env.reset() # initialize state
state_buffer, action_buffer, reward_buffer = [], [], [] # keep experience in buffers
rewards = 0 # accumulate rewards for each episode
done = False
# start episode
for t in range(self.episode_length):
state = norm_state(next_state, env.state_space.w, env.state_space.h) # normalize state values
# choose action and do action
action = self.lnet.choose_action(state)
next_state, reward, done = env.step(action)
rewards += reward
done = done or t == self.episode_length - 1
# store experience in buffers
action_buffer.append(action)
state_buffer.append(state)
reward_buffer.append(norm(reward, env.max_reward, env.min_reward))
# train
if total_steps % GLOBAL_UPDATE_RATE == 0 or done:
# push experience, update global network, clone back global network
push_and_pull(self.opt, self.lnet, self.gnet, done, next_state, state_buffer, action_buffer, reward_buffer, self.gamma)
state_buffer, action_buffer, reward_buffer = [], [], []
# transition to next state
state = next_state
total_steps += 1
if done:
# end of episode, update global information
record(self.g_ep, self.g_ep_r, rewards)
break
首先每個 worker 都繼承 mp.Process。mp 是 PyTorch 的 multiprocessing package,利用它來為每個 worker 建立不同 thread 讓他們能 run in parallel。
每個 worker 的架構都跟 global network 相同。run 的時候開始和環境互動取得經驗,每 GLOBAL_UPDATE_RATE 個 step 就會把經驗 push 回 global network,訓練之後,再把 global network 複製回來。可以想像有很多 worker 都在同時做這件事,增加效率。
最後是 training:
def train(env_params,episodes=200, episode_length=50):
# Global network
env = PoolEnv(**env_params)
gnet = Net(env.state_space.n, env.action_space.n, HIDDEN_DIM)
opt = SharedAdam(gnet.parameters(), lr=LR) # global optimizer
global_ep, global_ep_r = mp.Value('i', 0), mp.Value('d', 0.) # 'i': int, 'd': double
# Parallel training
workers = [Worker(gnet, opt, global_ep, global_ep_r, i, env_params, ACTION_BUCKETS, HIDDEN_DIM, episodes, episode_length, model_path)
for i in range(mp.cpu_count() // 2)]
for w in workers:
w.start()
for w in workers:
w.join()
SharedAdam 是特別進去原本的 Adam optimizer 讓裡面的 state 可以有效共享在不同 worker 中。簡單來說,我們建立一個 global network,以及一群 worker thread 讓他們同時跑在不同 thread 上,每個 worker 就像上面看到的一樣,收集完一些經驗就丟給 global network 訓練。
這算是我第二個 RL project,做完心得就是 RL 雖然好像很萬用很強大,但訓練起來真的需要一點經驗才能有好的成果。如果大家想要玩 RL,推薦先從簡單的開始建立經驗吧!
